Batch Processing in Workflows:
Batch processing is a powerful tool in Rubiscape that allows us to efficiently handle large datasets by dividing them into manageable chunks and processing them sequentially.
Understanding the Benefits:
Improved Performance: Breaking down large datasets into smaller batches reduces the overall processing time, makes our workflows run faster.
Efficient Resource Management: Batch processing optimizes memory usage by processing data in smaller chunks, freeing up resources for other tasks.
Simplified ETL Operations: Batch processing simplifies various Extract, Transform, Load (ETL) tasks like missing value imputation, data cleansing, and model testing.
Steps for Implementing Batch Processing:
-
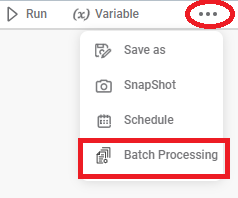
Select the Batch Processing Option:
• Navigate to the “Workflow” section in Rubiscape.
• Click the three dots on the top right corner of the desired workflow.
• Select “Batch Processing” from the displayed menu.
-
Set the Chunk Size:
• A pop-up window will appear with a default chunk size of 1,000 records, (e.g. chunk size of 3,000 records)
• This value determines the number of records processed in each batch.
• We can adjust the chunk size based on our dataset size and desired processing speed.
Note: Setting the chunk size to zero will result in an error.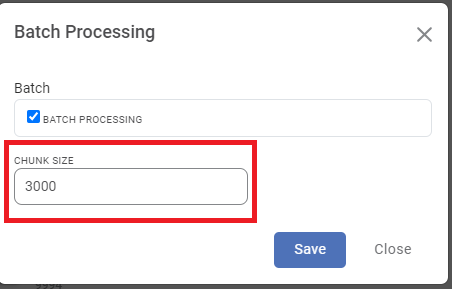
-
Visualize Batch Processing:
• Once we’ve confirm the chunk size, the data page will be displayed, reflecting the division into batches. (e.g. 6000 is the 2nd running batch)
• We can monitor the progress of each batch as it gets processed.
-
Explore the Output:
• After all batches are processed, the combined output will be available for further analysis.
• The maximum viewable records per page are limited to 1,000, with pagination for larger datasets.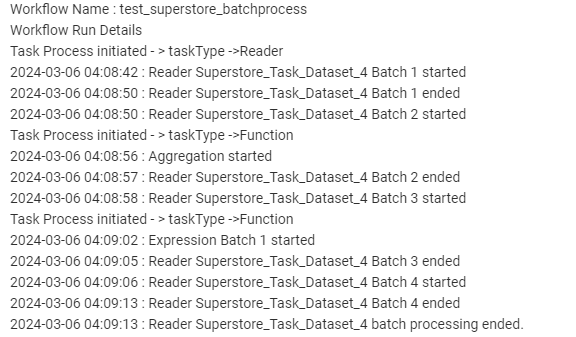

Additional Considerations:
Limitations:
• Batch processing is currently applicable only to workflows, not individual datasets or entire column operations like averages and totals.
• It’s not supported for datasets generated through SSAS RDBMS, Twitter, JSON files, and Google News.
Best Practices:
• Choose an appropriate chunk size based on your data volume and available resources.
• Monitor the batch processing performance to identify any bottlenecks and adjust the chunk size accordingly.